First off, I would like to applaud Cody Gulley (@Montrillian) for his article on Niche Gamer.
This is how scientific discourse on a topic should occur because this demonstrates several things: your strong feelings on a topic, your ability to understand your argument and most importantly, it shows respect for your opponent.
Statements where you are yelling your ‘feels’ have no place in science and you do yourself, your group, and your cause a disservice.
But civil discussions like @Montrillian‘s on Niche Gamer do one more very important thing: they allow individuals like myself the opportunity to understand why you feel the way you do about our data. It allows us an opportunity to explain why we designed the experiment the way we did. Because, believe it or not, there is a reason for why everything is the way it is.
And finally, if you notice that before the criticism of our study, @Montrillian briefly summarizes and states the positives about the study. This is common courtesy when reviewing someone’s paper in the scientific literature and demonstrates that you understand the purpose of the paper and acknowledge that the paper has some merits. This is high quality reviewing that even most reviewers don’t understand.
So I applaud you for being so courteous. I want to reiterate here that this is why I am responding because clearly Cody has taken time to put together cohesive arguments and is acknowledging me as an equal. This is why I do the same.
“To start with, the data that this study used was not current in the least. It was obtained from a study on Halo 3 conducted back in 2012, a point in time where the game was already five years old. While using the data from older studies is a perfectly acceptable practice, the researchers misrepresented the older data in such a manner as new and original. This is reflected in their results page which stated, “we played” rather than the more accurate “we obtained from the original data”. Due to the wording, readers are left with the false notion that this information is a current and accurate depiction of today’s gamer, rather than a reflection of the Halo 3 gaming community in 2012.
First to clarify, although the original experiment was published in 2012, it was not completed in 2012. Actually, it was completed much earlier when Halo 3 was in its prime. Thus, concerns about why an old game was used are unnecessary as it was one of the more popular FPS games at the time that the study was completed.
Second, @Montrillian is correct that the results are a representation of players at that time, but that in itself does not invalidate the results, because our argument is not that gamers are/aren’t sexist, but that performance and status have an effect on male behaviour toward same and opposite sex opponents in a male dominated environment.
As a result, it doesn’t matter the age of the game because the question is not one of a particular subset of the population. Although the media has spun our result into a “gamers are” study, it is a study on human behaviour that happened to use video games to test a larger question about human behaviour.
I cannot control the way the media spin results, and demonstrates the necessity for the public to read the primary paper. This is why we made it freely available.
“While the distinction was made in order to determine when females were more likely to receive sexist comments, it willingly ignored any sexist remarks directed toward men.”
It’s true that we did not examine whether the male treatment received any sexist language, but to my knowledge, there is no literature that suggests that men use sexist language towards other men. In fact, I’m not sure how this would occur given the definition of sexism.
The question that we set out to explore was whether men treat women differently than men in a male dominated environment. As a result, we did examine how many positive and negative statements the male treatment received from other male players as this was the basis of comparison to determine how many negative and positive statements the female treatment received. As a result, both treatments were examined in exactly the same manner.
This also provides me with an opportunity to state our initial hypothesis when we first started this study. We hypothesized that male players would use sexist language towards women (which they didn’t), and men would use homophobic language towards men (which they didn’t either).
We hypothesized these aspects because we thought that men would use language that had the potential to ‘rattle’ other players in the most efficient way. Perhaps we didn’t see this because we explored how teammates spoke to one another, rather than how opponents speak to one another (which is another interesting question I hope to explore).
“Without this critical piece of information readers and researchers alike cannot determine if the amount of negative sexist comments observed was normal for both male and female players, or if female players received a statistically significantly larger amount of sexist comments than men.”
Again, we show that men did not use sexist language towards women, and although we did not test whether men used sexist language against other men, there is no reason to predict that they should.
However, by comparing male player behaviour in the male treatment against male player behaviour in the female treatment, we did show that some men did behave more negatively towards women than men, and this behaviour was mediated by their performance and skill level. As a result, we can definitely say that women received a statistically greater number of negative comments from players that performed more poorly.
“If the former is true, then the findings would only prove that players who perform poorly are generally more negative than players who perform well, hardly the insight into gender norms and online gaming that the authors and media coverage billed it as.”
This statement is only partially correct. Male players that performed more poorly were only more negative in the female treatment, not the male treatment. This provides great insight into gender norms because it demonstrates that men alter their behaviour in response to the gender of their teammate and their performance — a facet that has not yet been demonstrated in the literature.
Additionally, we also demonstrate that players that perform well and were of higher skill were more positive towards the female treatment relative to the male treatment. An equally important finding and one that demonstrates the complexity of gender interactions.
“The study suffers from another major problem as it generalized old information to the public of today, without any indication of who comprised their sample demographic other than males who spoke when playing Halo 3 five years after it was released. This lack of information is partially due to the semi-anonymous nature of Xbox live pseudonyms, but lacking key information such as location, ethnicity, or age, makes it impossible to properly generalize this information to the public.”
As I stated above, we are not generalizing to the entire population of gamers, we are simply examining how men responded to male and female teammates as a consequence of their performance. Stating that it is ‘old data’ suggests that individuals behave differently now than they did prior to 2010, which is highly unlikely and an unfounded statement.
That being said, @Montrillian is correct here that we couldn’t collect any demographic information. I wish we could have gotten age and location, but this is a decision that is made at study design and there are costs and benefits to trying to gain this information. I’ll outline these below.
First, if we contacted individuals and asked them to provide demographic data, then we would need to tell them the purpose of the study which would inevitably change their behaviour. The information gathered in a study exploring negativity and sexism when players knew they were being recorded to see if they behave that way would be utterly useless since who would behave that way if they knew someone was watching? This is called the ‘social desirability bias‘ and is a well-known effect that is known to skew human behaviour.
In our study, although we cannot determine individual age, we can state with 100% certainty that individuals are behaving in their normal behavioural patterns. To me, exploring how individuals honestly behave provides the opportunity to understand what behaviours are natural is the important first step.
Then, once we know if a behaviour occurs, then the next step is to explore what other factors (like age, ethnicity, etc) affect those behaviours. This is why we did it this way. It’s not perfect (no data ever are), but I stand by this decision because this is the best way to first determine whether there is an effect.
Second, stating that all the players were likely teenagers would require demonstrating that teenagers make up the majority of the Halo 3, demographic. and this is not published. Personal interactions with younger teenagers do not validate the average age of players. But we can make some assumptions based on some available information.
Halo 3 is a game rated M (Mature) and although there are likely to be young teenagers playing the game, the majority of individuals should at least be 17. Additionally, it is unlikely that teenagers made up the majority of our sampled population given that the average age of gamers in 2010 was 34. As a result, we feel that this is a reasonable sample of the average individual that played Halo 3 at the time.
“They did not even record the one bit of demographic information that was available to them, player skill.”
Yes we did. And I will get to that below.
“Without the necessary demographic information, it is not possible to determine the significance of the data in relation to the general public.”
I respectfully disagree with this statement. First, although our data doesn’t perfectly identify the role of demographics, it does allow us to generalize to the population.
For example, if we look at Jungle Jumping on Google Play app (I just picked this randomly), we can see that it’s been downloaded over 100,000 times. We can also see that there are 3,599 ratings. We don’t know any of the demographic factors of the individuals that rated the game, but we can say that based on these individuals’ ratings, it seems like it’s a well-liked game at 3.8 stars.
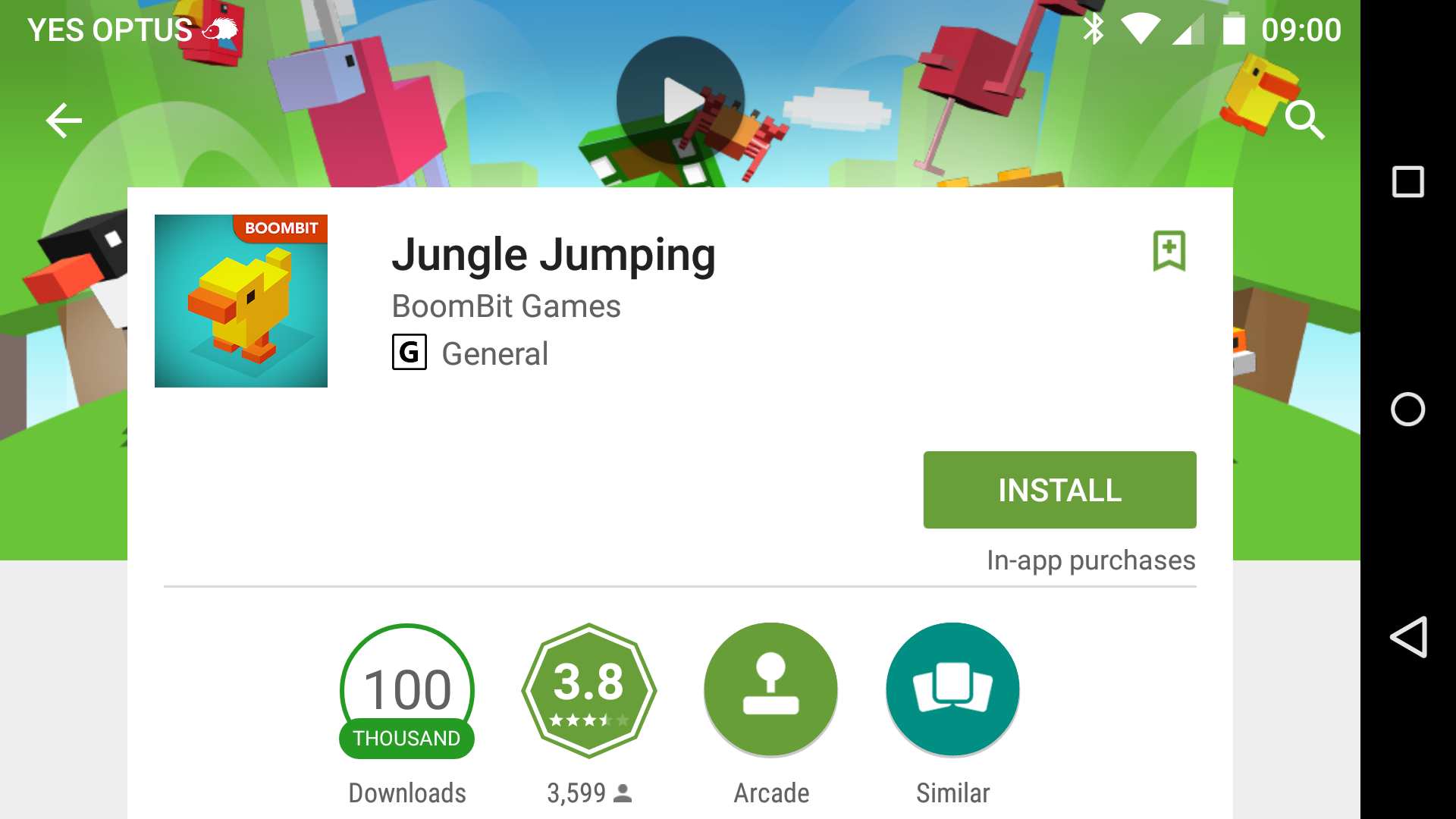
Would understanding demographic details provide another level of nuance — absolutely. The fact that we don’t have any other details doesn’t, however, invalidate the ratings it just provides a general understanding of what the average individual thinks about the game.
“even attempting to control for such factors, the author has attempted to convince the public that the only reason for such sexist attitudes is the fact that a woman is performing better than a man in a game, and nothing else.”
This is a common criticism I receive even from seasoned reviewers, and here’s the problem with this statement — it is absolutely impossible to control for everything. Imagine the sample size you would need to control for age, gender, education, socioeconomic status, religion, ethnicity, etc. — each would require a minimum of doubling the sample size.
Instead of controlling for each factor, the ideal way is to randomly place participants in a trial and manipulate which treatment they receive — which we did by using a male or female treatment. Due to creating such a design, what we are able to ask is that all other aspects being random, does the factor that we are manipulating have an intended effect.
Because we are creating an experiment, we are acknowledging that individual variation exists, and given that we can’t control for all the variation, we will increase our power by performing a manipulation. Our results thus definitely provide evidence that individual performance and skill affect how often male players use positive and negative comments to a male or female teammate.
What our experiment does not do is prove that other factors are not important. And nowhere in our study do we suggest that no other factors are.
“While the researchers didn’t control for factors such as age, nationality, location, or even ethnicity, they did make sure to carefully explain just what information was used. In total, the older study from which the data was obtained had 1136 participants, with roughly 574 participants played against the female voice, and 567 played against the male voice. However, these exact figures were omitted from the study because the author made sure to write only what he thought as “necessary” for the reader to come up with their own opinion.”
I would like to be very clear here: at no point were we trying to fool our audience about how we attained our sample size. This is why we tried to be as clear as possible with our methodology and numbers by providing the number of players, the number of games, and the number of speaking individuals (I discuss this further below), and why we provide the data and code.
The exact numbers are never omitted at any step and we state with exact clarity how we ended up with the final numbers we used.
“This necessary information meant only looking at the participants that actually spoke, which ended up being 189 participants. While it is easy for a casual reader to assume the fact that people didn’t talk meant this information wasn’t useful, it is critical for researchers to publish all of the information that they obtained. The importance of including such “unnecessary” information means the difference between a figure of 1.9% or 13.4% of participants using sexist comments once it is stripped of context such as in media coverage, a figure which is seven times greater than initial findings.”
I’ve also had this criticisms from a few folks on twitter, so I will ask here what I asked them (they never responded). When exploring what people say to teammates based on their gender, to me this means that you can only explore the data in people that say anything.
How does one gain information on what someone who doesn’t speak is thinking?
Let’s jump back to the Google Play example above. Since we had 3,599 people respond and rate Jungle Jumping, we can say that these 3,599 people had strong enough feelings to provide information of what they thought of the game.
Let’s say for the sake of argument that 2000 people gave the game a 5 star rating. That’s 55.6% of individuals. Should we go ahead and say that it’s not actually 55.6% of individuals but 20% of individuals because we should count all the individuals that downloaded the game?
Of course not. That’s because we have no idea what they think about the game. It may be that all the other individuals that didn’t rate the game loved it so much that they’re not even taking the time away from it to rate it. Or it could be that they all hated it so much that they immediately removed the game.
Or it could be that the 3,599 individuals that rated the game, on average, describe the feelings of all the other individuals that didn’t rate the game.
This is the same thing in our study, of the people that decided to voice their positive and negative behaviour, people who performed poorly were more likely to be more negative to a female treatment, and those that were higher skilled were likely to be more positive to the female treatment.
 As you can see to the left, there are positive and negative reviews that different individuals provided. These reviews do not speak for everyone, but they give us an indication of what people think.
As you can see to the left, there are positive and negative reviews that different individuals provided. These reviews do not speak for everyone, but they give us an indication of what people think.
This is the same for our study. The data does not speak for ALL Halo 3 players (and especially all gamers), but does provide insight into the behaviour of players that did behave, and we can use those data to provide an average picture of what affects individual behaviour.
I can see that readers may think we are biasing data by not using the individuals that didn’t speak as proof that they are not negative, but we don’t know what they really thought and assuming they thought one way over another is a preconceived bias.
As a result, it is best to remove them from the analysis and focus on the individuals whose behaviour you can identify with absolute certainty.
“One of my old statistics professors told me in my undergrad program that you can prove anything using statistics. Change the amount of participants in a study and you can prove that raising the temperature in a classroom can improve the likelihood of scoring an A on a final exam. This is what the researchers proved, if you manipulate the data enough, you can show that male gamers who play poorly will make sexist comments toward women while losing.”
Yes, you can “prove” anything using statistics, but that’s where strong experimental design and an open explanation of how the data were collected and used comes into play. And @Montrillian, you admitted that the design was good (paragraphs 4 and 5 of the original article).
Hopefully my explanation above convinces you that we didn’t manipulate the data, but instead used the data to explore the behaviour of those that behaved, and didn’t assume the behaviour of those that didn’t behave.
Along this topic, I came across a really interesting article here that you might find interesting if you’re into stats.
“Out of every player that participated on the female side of the study, only 1.9% displayed a sexist comment. That is 11/574 (or 1.9%), breaking that down to only players who were active teammates of the female experiment, and we’ve are left with 11/246 (or 4.47%). If we reduce the numbers further to only the 84 participants that actually talked and we’re at 11/84 (or 13.4%) of all participants using sexist remarks.”
I hope this is clearer now. But regardless, we show almost no use of sexist language. We show changes in hostile and amicable comments — that is the focus of the paper. There is no value in criticizing our paper for a results we openly admit is not significant.
“This generalization promoted by manipulated data is far from the only overgeneralization due to inconsistent, or incomplete data. Factors such as Playlist Rank are more dependent on the amount of time played than on skill. This Playlist Rank system only takes the amount of times a player has won or tied, lost, or disconnected into account, rather than factors such as cooperation, assists, or even driving vehicles, let alone a proper kill to death ratio. In this study, Rank is believed to be a “status symbol” that shows “dominance” to the other players, rather than a factor that could easily be manipulated, or paid for.”
One, of course, can easily argue that individuals that play more often are on average of greater skill — that’s because they practice more, and this is the case in anything we do, including video games. Should we not assume that someone that plays soccer 2 hours every night is going to be ranked as a better player than someone that plays 2 hours each weekend?
Of course. As a result, the skill level accurately reflects how individuals are likely to scale relative to other players.
And yes, skill can be manipulated and paid for, but there is no reason to believe that all the players did this, and that the distribution of those that did manipulate or pay for the skill varies in the two experimental treatments. This is why randomly assigning players and using an experiment is such a powerful way of answering a question.
And it’s true that the skill level doesn’t take into consideration assists, driving vehicles, etc. But I will answer that below.
“A second factor this study tries to use is a kill-death ratio to show skill of the player. The amount of kills you have over the amount of deaths you’ve had typically show your general level of skill according to the study. Again this takes out all cooperative team-like behavior. Just because a player isn’t killing the opposing team doesn’t mean they aren’t a credit to their team. Assists matter in a team-based game, driving the vehicle while others take the kill is important. By removing these important factors the data cannot accurately represent who performs the best in a team-based game like Halo 3, and skews the data to only show players who take aggressive action as dominant.”
First, I would like to be clear that we didn’t use a kill-death ratio (K-D ratio) because there are inherent problems with ratios. For example, someone that kills 5 opponents and dies 25 times has the same ratio as someone that kills 1 opponent and dies 5 times. These two aren’t the same thing.
We used the number of kills and deaths separately which explores actual performance.
That being said, the points that that assists and the like are not counted are true. But we have to ask an important question: does the addition of assists, or going even further, the assists-of-assists make the data stronger? I would argue no, and here is why.
Let’s take professional NBA players for instance. A game is won by outscoring the opposing team. Outscoring the other team is done by either scoring more points than the other team, or preventing the opposing team from scoring points (and to some extent, both). This is equivalent to kills and deaths, in our experiment.
Although players on an NBA team can help each other score points by assisting them, it is the scoring of the points that gains the most benefit, not necessarily the assisting (even though that is an integral part of the game).
If we are to stack all NBA players in a given year in a column by the number of points scored, we would, with pretty good accuracy, be able to identify the best players in the NBA for that season. This of course wouldn’t describe all their abilities (block, rebounds, etc.), but it would be a pretty accurate estimate of their skill as an NBA player.
This is what Halo 3 does with kills and deaths. It stacks individuals in a column and rates them on these two factors. Are other factors important? Yes. Does kills and deaths give us a good enough idea of which players are best in a specific game? Yes.
Additionally, I argue that kills and deaths are extremely important indicators in Halo 3 because you can immediately see how you’ve performed relative to others in a match at the end of the game since Halo 3 specifically goes through the trouble of highlighting these factors to each player at the end of the game.
As a result, we feel that kills and deaths are good estimates of player performance (especially in deathmatches used in this study) and do not see how the addition of other particular factors would increase the accuracy of our experiment.
“This study did show statistical significance for several interactions between the experimental player and the participants. It is important to understand that statistical significance is not proof of the conclusions they draw from it, rather that the likelihood of these events occurring again is greater than random chance. Given the small sample size, even the variation due to chance is quite large.”
I feel that there is a little confusion here. Please correct me if I am wrong, but what I think you are trying to say that because our results are significant, the likelihood of these events are occurring is greater than random chance, but it still questions whether this has biological meaning in real-world scenarios.
I would argue that given our initial predictions, which we test with very specific models, it does describe a situation that is both statistically significant and has real-world explanatory power.
As a side note, there is an excellent interview with Ben Bolker, a phenomenal statistician that is at the forefront of statistical analysis. It’s very much worth a read if you’re interested in statistics.
“This data was used to say that people who are bad at playing games are sexist. This study only had 11 participants say sexist things, but 11 participants became the public at large. This is why everyone should learn how to analyze a scientific paper, if only to come to your own conclusions.”
Exactly!
We have almost no use of sexist language and the media portrayed gamers as saying sexist things. That being said, we did show that players behaved more aggressively towards women when their performance was poor. We were very clear in our paper and in the pop science article we wrote at The Conversation. This is why we made the paper, data, and code freely available.
What Gamergate should be doing is using the open access paper and data to tell media outlets that they misreported the findings. They should not be accusing the authors of unethical behaviour where there is absolutely no evidence for any.
I hope that I have sufficiently answered the comments about our paper. If not, let me know.
In addition to this, there has been a question about the statistical analyses used to analyse our data, suggesting that we used the wrong test because of overdispersion in the data.
We have since proved that comment to be incorrect and also feel that it was disingenuous because they neither provided the data or code for their analysis, nor did they provide the parameters for their analysis. Performing a poor analysis and hiding how you did it will not prove anyone wrong. If you are interested in that comment and our response, you can find it on the PLoS ONE site.
But this also bring up another point. It’s important to question research. This ensures that scientists are honest and the research is performed without bias. That being said, to accuse a scientist of misrepresenting the data without asking them why they did what they did (which was not the case in the article in Niche Gamer) is disingenuous. We are exploring data and have been trained in doing so for extended periods of time.
Although you may ask a builder why they did a certain thing when building your house, you wouldn’t accuse them of not knowing how to build a house if they’ve successfully been doing it for 20 years. The same can be said about teachers, physicians, nurses, psychiatrists — these are all individuals that underwent an extensive period of training to perform the tasks that they do. Scientists and researchers are no different.
I would like to personally thank you for providing a response to the Niche Gamer article on your study. I find that there aren’t many people out there who are willing to have polite discourse over criticism, especially after having such a strong push back from gaming population. While I still have my own problems with the kill/death statistics being used as an accurate representation of player skill in a team based game, I found your points over why you did not include male-on-male sexist comments, and your reasoning for using the small percentage of talking players to be quite convincing.
Again, I would like to thank you for being polite and civil in your response,and I wish you luck in your future endeavors.
I believe the argument he’s making is that the small sample size & the amount of things tested in the original data makes it more likely that SOMETHING will be significant.
There have been a few other pieces of criticism of this study. Here is one from A Voice for Men:
http://www.avoiceformen.com/feminism/new-study-does-not-show-that-gamers-are-sexist/
I’m wondering if you would care to comment?